
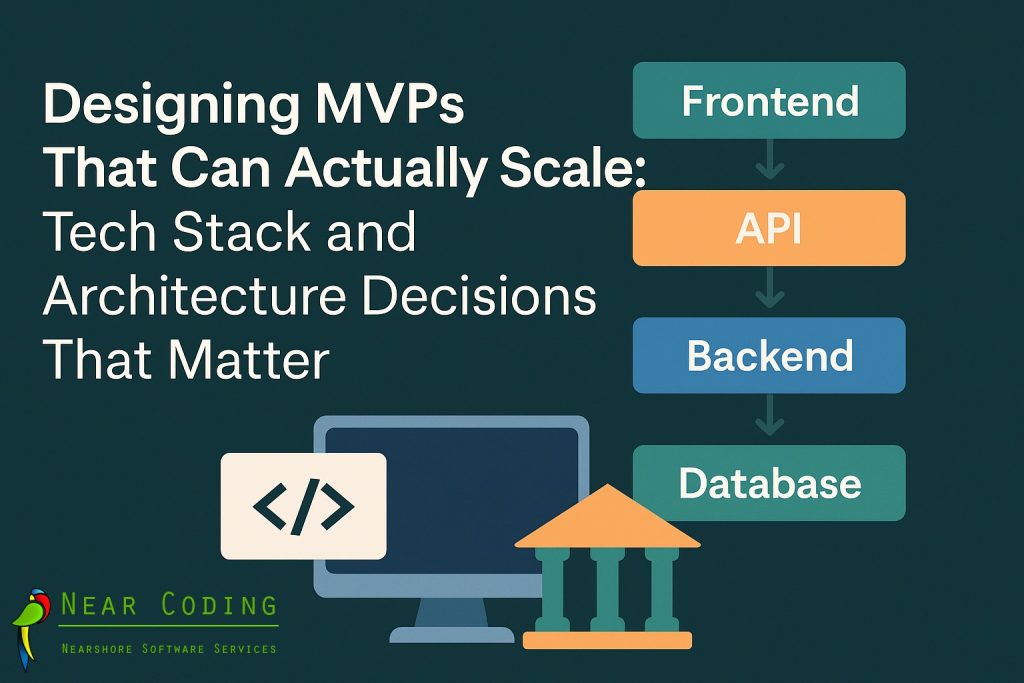
2. MVP Philosophy: Building Just Enough But Building It Right
The term Minimum Viable Product (MVP) is frequently misunderstood. While it has become a startup mantra, its misapplication is responsible for a large percentage of technical failures in early-stage products.
Many founders equate “minimum” with disposable, like creating systems with just enough functionality to demo or pitch, but without a strategy for what comes next. In reality, a well-designed MVP is not a shortcut. It’s a strategic foundation: the first iteration of a system that will (ideally) support months or years of growth.
At the core of this philosophy is a simple principle: build just enough to validate your riskiest assumptions, but do it with structure and intent. And that means embedding MVP Architecture Best Practices into the product’s very first lines of code.
What constitutes “just enough” depends entirely on your context:
For a B2C mobile app, it may be a working onboarding flow and referral system.
For a B2B SaaS, it might include billing, permissions, and audit logs from day one.
For a regulated industry MVP (like fintech or healthtech), compliance constraints mean you can’t skip certain infrastructure elements, even at the MVP stage.
This is why Custom MVP Development is so critical. There is no one-size-fits-all template. Your MVP must be tailored to your business model, user expectations, and technical risk areas.
The Architecture Trap: Speed vs Scalability
The biggest pitfall in early MVP work is over-optimizing for speed at the cost of structure. It’s understandable — timelines are tight, investors are impatient, and users are waiting. But this short-term mindset leads to brittle architectures that collapse under success.
Instead, the MVP should be treated as the first implementation of your system’s core contracts — its domain logic, service boundaries, and data models. Scalable MVP Development doesn’t mean introducing microservices, Kubernetes, or enterprise patterns. It means using a well-composed, modular architecture that can grow without major rewrites.
Architecture Guidelines for a Healthy MVP Core
Here are the foundational practices we apply when designing MVPs intended to scale:

These are the MVP Architecture Best Practices that give you flexibility later, to introduce caching, refactor APIs, or extract services with less risk and effort.
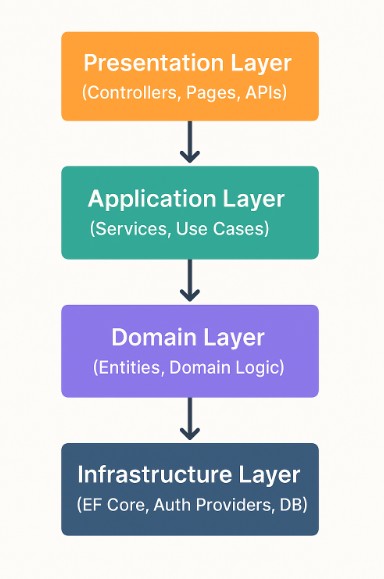
In the pattern, the Controller is the entry point. It handles HTTP requests, validates inputs, and delegates the real work to the Service layer. The Service contains the application’s use cases, orchestrating business logic without worrying about how data is stored or how requests arrive. To persist or fetch data, the Service calls an interface (e.g., IUserRepository), which is implemented in the Repository layer. This repository is the only piece that interacts with the database, keeping persistence logic isolated.
Requests and responses move through DTOs, ensuring that external clients only see what the API allows. Inside the system, Entities represent the business domain and enforce rules and invariants. This means DTOs carry data across boundaries, while Entities preserve integrity inside the domain.
This separation works because every layer has a single responsibility. Developers can swap the database, change the authentication provider, or add caching by only modifying the repository or adapters. Testing becomes easier too: services can be unit-tested with mocked repositories, and domain rules are validated without touching the API or the database. For architects and product owners, this structure provides clear boundaries, less risk of regressions, and a roadmap for evolving from monolith to modular systems.
For the business, the payoff is speed and resilience. Features ship faster because teams work in parallel on isolated modules. Bugs are fewer, since logic isn’t scattered across controllers and views. Users benefit from more reliable applications, while the company gains products that are scalable, robust, and maintainable. In short, this architecture helps everyone: developers by reducing complexity, product owners by enabling faster pivots, and the company by avoiding costly rewrites while building MVPs that can truly grow.
Notes:
This setup follows MVP Architecture Best Practices in .NET by keeping each layer cleanly separated.
The
IPasswordHasherinterface allows easy testing and swapability for external auth services like Auth0 later.The DTO pattern avoids leaking database models into the API surface, a key consideration in Scalable MVP Development.
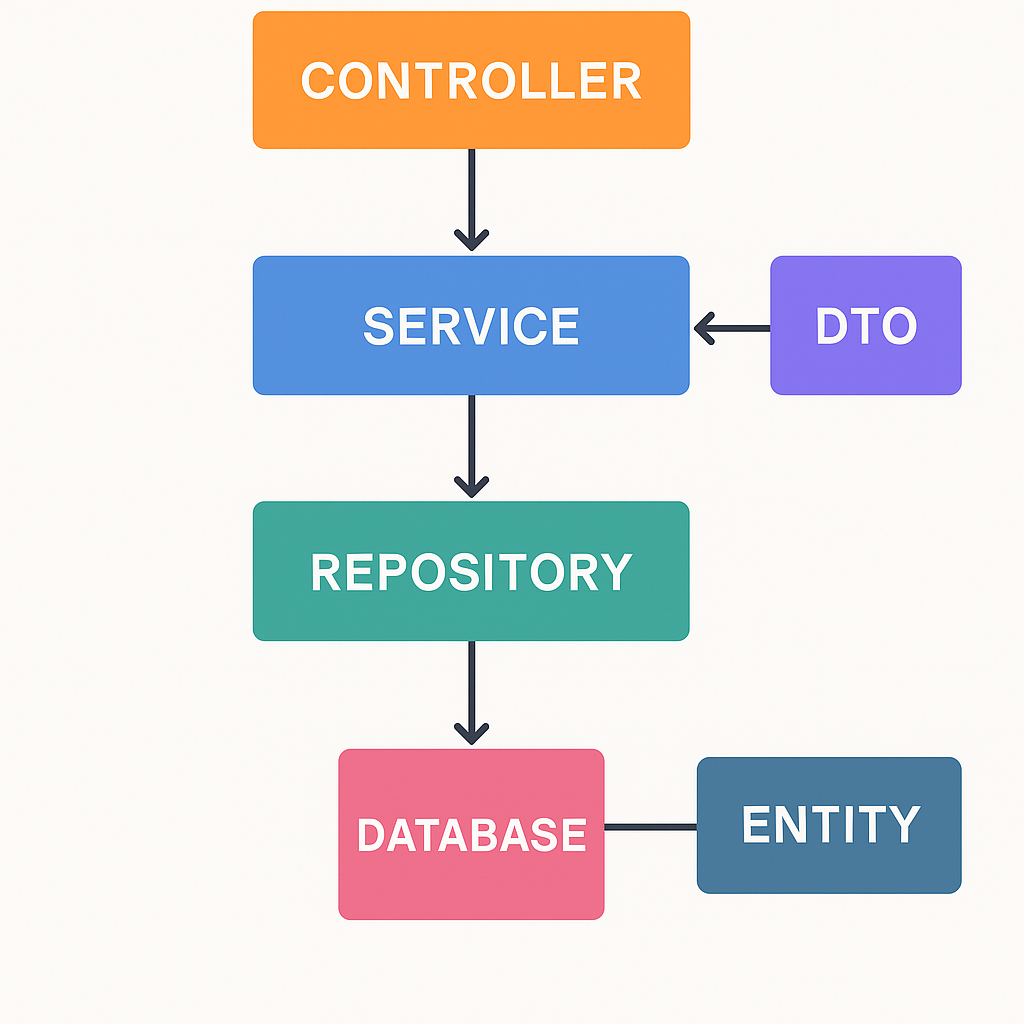
Controller → handles HTTP and delegates.
Service → contains use cases, consumes DTOs, orchestrates rules.
Repository → manages persistence, communicates with DB.
Entities → represent the core business model.
DTOs → carry data across boundaries.
When to Cut Corners and When Not To
In our work with startups and enterprise innovators alike, we apply a simple rule: cut corners where you can safely refactor later, not where change will be expensive or risky.
✅ Acceptable shortcuts:
Using Bootstrap or Tailwind over a custom UI library
Storing images on S3 without CDN integration at first
Hardcoding some configuration before moving to ENV vars
🚫 Dangerous shortcuts:
Tightly coupling controllers to business logic
Writing to the database directly from views
Mixing user authentication with business rules
Skipping basic testing on core flows (auth, payments)
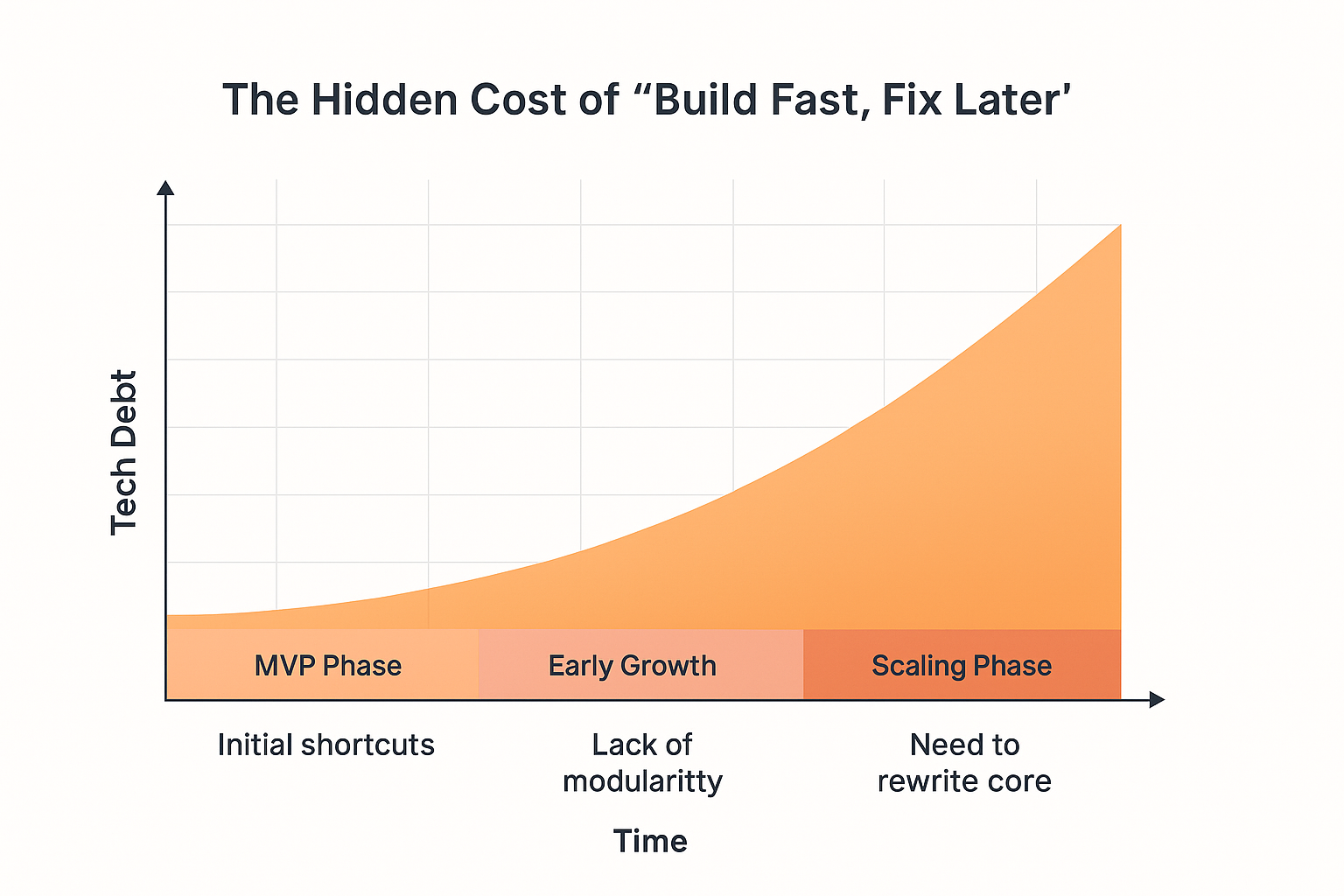
The cost of technical debt is non-linear. Early mistakes compound rapidly, especially when your MVP gains traction faster than expected.
3. Foundation First: MVP Architecture Best Practices
Behind every successful MVP that scales lies a clear architectural backbone: one that balances speed of delivery with long-term stability. Unfortunately, many MVPs are built as fragile monoliths or duct-taped microservices that crumble under early success. The reason isn’t lack of talent, it’s lack of structure.
At Near Coding, we approach every MVP as a launchable product with a scalable foundation. Whether we’re working with a startup founder or a corporate innovation team, our commitment is the same: make smart, minimal, but intentional architecture choices that support growth, pivots, and future refactoring without starting from scratch.
This section explores the MVP Architecture Best Practices that should guide every Custom MVP Development project.
Why Architecture Still Matters at the MVP Stage
You don’t need microservices, message queues, and distributed caching to validate an idea. But you do need clear separation of concerns, modular code, and service boundaries that won’t break when you go from 10 users to 10,000.
What matters most at the MVP stage:
Clear domain layers that separate logic from infrastructure.
Internal APIs that make feature reuse and testing easy.
Adaptable persistence so you can evolve schema without pain.
A modular structure to allow team scaling later.
The good news: these patterns don’t slow you down. Done right, they accelerate development because they reduce friction, confusion, and rework.
Core MVP Architecture Best Practices
Let’s break down the most essential best practices that apply across stacks (.NET, Node.js, Django, etc.):
1. Domain Isolation
Why it matters: Business rules should live independently of APIs, databases, or UI changes.
Practice: Use classes or modules to encapsulate logic. Avoid “fat controllers” or logic in Razor views, React components, etc.
This improves team parallelization, reduces cognitive load, and aligns to domain boundaries.
5. Bounded Contexts (Even in a Monolith)
MVPs don’t need microservices, but they do need bounded contexts. For example:
Authentication logic should not bleed into the eCommerce module.
Notification services should be abstracted.
Use internal APIs or interfaces to enforce boundaries even in a monolith.
MVP Anti-Patterns to Avoid

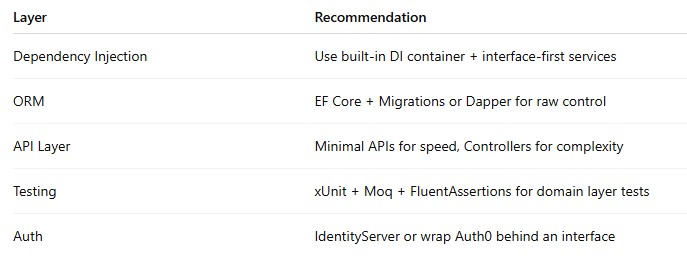
Tech-Stack-Specific Tips (Scalable MVP Development in .NET)
If you’re using ASP.NET Core, here’s what we recommend from the start:
Sample Architecture Folder Structure in .NET
4. Choosing the Right Tech Stack: What Smart CTOs Know
One of the most defining choices in Custom MVP Development is the tech stack. It determines how fast your team can move, how costly scaling will be, and how maintainable the system remains after launch. Choosing the wrong stack doesn’t just slow development, but it can lock your product into an expensive corner of technical debt.
A smart CTO approaches this decision as a balance between time-to-market, team expertise, and scalability potential. The goal isn’t to chase the trendiest framework but it’s to select tools that minimize risk while allowing the product to evolve gracefully as it gains users, features, and complexity.
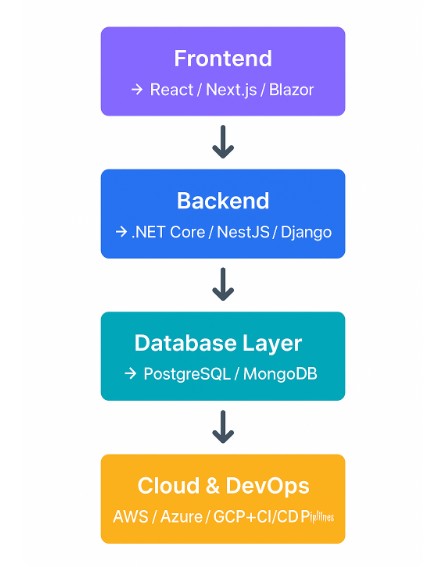
The Three Pillars of a Scalable MVP Tech Stack
1. Developer Velocity
Speed matters, but not at the expense of clarity. Choose frameworks with strong community support, good documentation, and rapid development patterns. React, Angular, or Blazor for front-end and frameworks like ASP.NET Core, Node.js (NestJS), or Django REST for backend enable quick iteration with structure.
2. Scalability and Performance
Your MVP won’t stay “minimal” forever. Pick technologies with proven scaling stories—languages and frameworks that can handle increased traffic, data volume, and API load without a rewrite. Using containerization tools like Docker and orchestration systems like Kubernetes early on (even for staging environments) ensures future scalability.
3. Maintainability and Team Expertise
A perfect stack in theory is useless if your team can’t work efficiently with it. A stack aligned with your developers’ strengths shortens development time and reduces onboarding friction. Long-term, it means faster debugging, cleaner codebases, and predictable sprints.
MVP Tech Stack Comparison Table

How Smart CTOs Think About Tech Stacks
Smart CTOs don’t just pick a stack, they design an ecosystem. They know that technology must serve both product velocity and business adaptability.
When selecting technologies, they ask:
Can this stack handle both MVP and long-term scale?
Is the learning curve acceptable for the team we have?
How easily can we integrate 3rd-party APIs or pivot to new features?
Will maintenance costs remain reasonable as our codebase grows?
This mindset turns Scalable MVP Development into a long-term investment rather than a short-term experiment.
Diagram: MVP Tech Stack Ecosystem
Tech Stack Mistakes That Break MVP Scalability
Choosing trendy tools over proven frameworks — great for a hackathon, terrible for production.
Ignoring DevOps early — manual deployments always turn into emergencies later.
Skipping database migrations — schema chaos kills iteration speed.
Underestimating API design — tight coupling between front and backend limits flexibility.
Building without monitoring — logs and metrics must exist from day one.
How Near Coding Approaches Tech Stack Selection
At Near Coding, we analyze each client’s product goals, team capabilities, and growth projections before proposing a stack.
We build around principles of Scalable MVP Development:
A modular monolith that can evolve into microservices.
A predictable CI/CD pipeline for reliability.
Infrastructure-as-code for portability and disaster recovery.
Predefined logging and monitoring strategy for real-time insight.
This approach gives our partners a powerful balance: fast time-to-market with the confidence that the foundation won’t collapse when success arrives.
5. Scaling Pathways: Monolith First, Microservices Later
When building an MVP, one of the most strategic architectural choices you’ll face is whether to start with a monolithic structure or jump straight into microservices.
The temptation is understandable—microservices sound scalable, modern, and enterprise-ready. But in reality, they often add unnecessary complexity too early in the product’s lifecycle.
For most startups and new ventures, the smartest approach to Scalable MVP Development is to start monolithic, but modular. A well-designed monolith can scale impressively far while keeping your system simple, your team efficient, and your costs manageable.
Why Monoliths Still Win for MVPs
A monolith is often misunderstood. It doesn’t mean “spaghetti code in one project.” It means a single deployable unit that houses multiple bounded contexts (features, modules, or domains) within a clean architecture.
When built with MVP Architecture Best Practices, clear separation of layers, service boundaries, and modular structure, it becomes both fast to develop and easy to evolve.
Advantages of a modular monolith:
Speed of development: No distributed system overhead or inter-service communication setup.
Simplified debugging: One codebase, one log stream, one deployment pipeline.
Easier refactoring: Boundaries can shift as the business model changes.
Lower infrastructure cost: Fewer containers, no service mesh or queue management.
This approach allows you to validate your product idea and generate revenue before committing to the operational costs of microservices.
When—and How—to Transition to Microservices
As the product matures, feature modules that reach operational or performance limits can be extracted into independent services. This is when Custom MVP Development evolves into a distributed system, intentionally, not prematurely.
You’ll know it’s time to transition when:
Independent modules scale differently (e.g., “Billing” needs horizontal scaling but “User Profiles” doesn’t).
Deployment frequency diverges (teams need to deploy features without affecting others).
Performance isolation is required (e.g., one module’s load impacts another’s response time).
Team size grows (multiple teams can own separate service domains).
At this stage, you’re not “rebuilding”—you’re extracting. The modular monolith’s clear boundaries make service decomposition smooth. The service becomes a deployable artifact with its own database and CI/CD pipeline—reusing much of your existing architecture.
Diagram: Scaling Pathway – Monolith to Microservices
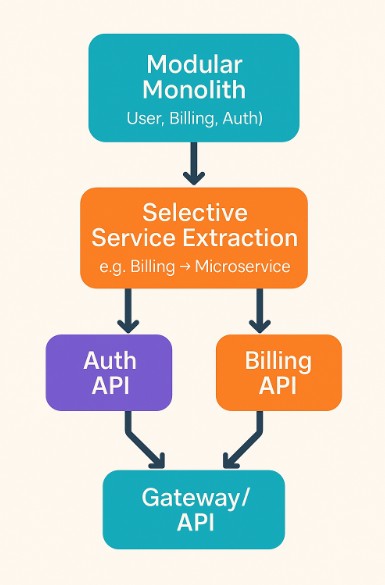
This evolution shows how a monolithic MVP can gracefully grow into a service-oriented architecture without costly rewrites.
Architectural Mindset: Design for Evolution
Smart architects plan for evolution, not perfection. Your MVP’s architecture should make change inexpensive.
That means:
Keeping clear service boundaries (even inside the monolith).
Using internal APIs or interfaces for feature communication.
Avoiding circular dependencies between modules.
Logging and monitoring each feature’s performance independently.
This makes your MVP refactorable, an essential trait for scalability.
Near Coding’s Approach: Modularity That Scales
At Near Coding, we help our clients build MVPs designed for change. We use MVP Architecture Best Practices to ensure that even monolithic projects maintain internal modularity. When the time comes to scale, the transition is seamless—not a rewrite, but a reorganization.
By focusing on Scalable MVP Development, we give startups the flexibility to start simple and grow strategically. This architecture-first mindset results in software that’s robust, adaptable, and aligned with the business for today and tomorrow.
6. The Role of DevOps and CI/CD in MVPs
When an MVP starts gaining traction, development speed and operational reliability become critical. It’s no longer just about building features, it’s about ensuring that every new release is deployed safely, consistently, and quickly. That’s where DevOps and Continuous Integration/Continuous Deployment (CI/CD) practices become indispensable.
Even for lean teams, incorporating a lightweight DevOps foundation early is one of the smartest moves you can make in Scalable MVP Development. It keeps the development process agile, reduces human error, and lays the groundwork for scalability long before traffic or complexity spikes.
Why DevOps Matters for MVPs
In traditional setups, developers write code and “throw it over the wall” to operations. In fast-moving MVP environments, that model breaks immediately. DevOps closes that gap with integrating development, testing, and deployment into one automated, observable cycle.
Benefits of adopting DevOps early:
Speed: Push code to production faster, multiple times a day if needed.
Consistency: Every environment (staging, production) behaves predictably.
Quality: Automated tests catch bugs before they reach users.
Confidence: Developers deploy with less risk, product owners see faster validation.
DevOps isn’t about adding complexity; it’s about removing uncertainty.
How CI/CD Fits into Scalable MVP Development
At its core, CI/CD automates the process of integrating code, testing it, and delivering updates to users. For an MVP, this means every new feature, bug fix, or experiment moves from commit to deployment without friction.
Here’s what a minimal but powerful CI/CD pipeline looks like:
Continuous Integration (CI)
Developers merge code to a shared branch (e.g.,
main) frequently.Automated builds and tests run instantly (unit, integration, API).
Failures are caught early—before merging.
Continuous Deployment (CD)
Once tests pass, the new build is automatically deployed to staging.
After review or automated approval, it’s promoted to production.
Rollbacks are easy, and version history is clear.
By combining these practices, your MVP can evolve rapidly with stable, reproducible deployments—essential for growing products and distributed teams.
Diagram: Simplified CI/CD Flow for MVPs
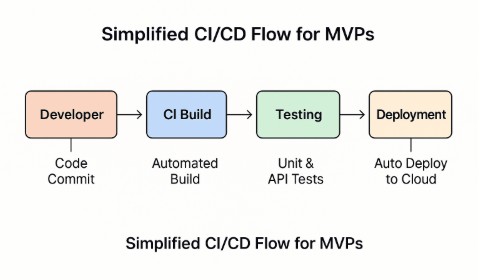
CI/CD transforms MVPs from fragile prototypes into living systems that can grow and adapt with zero downtime.
DevOps Tools for Custom MVP Development

These tools are not just for large enterprises. Used correctly, they empower small teams to achieve the same reliability and velocity that big tech companies enjoy.
The Near Coding DevOps Philosophy
At Near Coding, we approach DevOps as a strategic enabler, not an afterthought. Every project, no matter how early, includes basic automation, version control discipline, and structured environment management.
Our DevOps pipelines are designed around:
Zero-friction deployments: No manual steps or late-night emergencies.
Consistent environments: Staging mirrors production exactly.
Instant feedback loops: Test failures, performance drops, and code regressions are surfaced immediately.
This approach lets our partners scale confidently. Developers focus on creating features. Product owners get continuous feedback. Businesses save time and avoid the “deployment chaos” that kills momentum in early-stage products.
7. MVP Data Architecture: Think for Now, Plan for Later
Behind every scalable MVP lies one of the most critical (and often overlooked) components: data architecture. The way you design your database structure and handle data flow during the MVP phase will determine how much pain (or freedom) you’ll experience as your user base grows.
Most early-stage products start with a single database and a handful of tables. That’s fine. But problems arise when those tables grow unbounded, or when schema design choices made for speed today block scalability tomorrow.
Smart teams treat data architecture as a living asset: simple enough for an MVP, but structured enough for the future.
Designing Data Architecture for Growth
A scalable MVP data layer should prioritize clarity, modularity, and evolution. The goal is to ensure that your schema, indexing, and relationships can expand without forcing painful rewrites.
Key best practices include:
Start relational, stay flexible: For most MVPs, a relational database like PostgreSQL is ideal. It balances strict data integrity with JSON support for unstructured data.
Design for change: Use migrations (via EF Core, Prisma, or Flyway) to version your schema so that every change is traceable and reversible.
Modularize your schema: Keep domain entities (like Users, Orders, Subscriptions) separate to prevent tangled relationships.
Plan for analytics: Include basic auditing fields (e.g., created_at, updated_at) from day one to enable future analytics and reporting without retrofitting.
When to Use NoSQL vs SQL
Choosing between SQL and NoSQL is a classic architectural dilemma. For MVPs, SQL is usually the right default. It provides structure, data integrity, and consistency that support fast iteration and reliable testing.
However, certain scenarios justify introducing NoSQL elements:
When dealing with large unstructured data (e.g., user-generated content, IoT logs).
When the product relies heavily on document-based storage (like flexible user profiles).
When scalability and horizontal partitioning (sharding) are crucial from the start.
The best approach for Custom MVP Development is often hybrid: use SQL for transactional data and NoSQL for event logging or cache storage. This balance gives you the best of both worlds: consistency and scalability.
Diagram: Simplified MVP Data Architecture
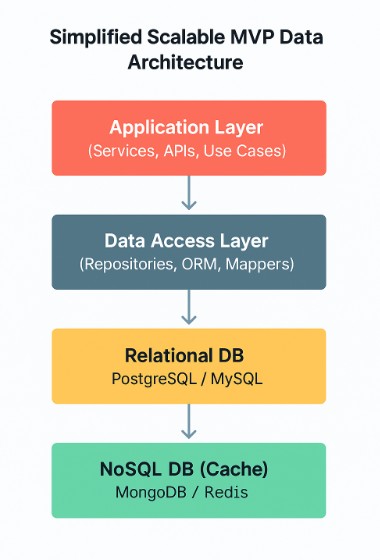
Hybrid MVP data architectures combine structured consistency with flexible performance, ready to grow without major redesigns.
Best Practices for MVP Data Evolution
Plan for schema versioning: Use structured migration scripts so that database updates are reproducible and reversible.
Avoid hard-coded data dependencies: Keep business logic in services, not in stored procedures or triggers.
Use soft deletes and audit trails: Deleting records should never mean losing traceability.
Monitor data growth: Introduce metrics early to track query performance and data volume trends.
Abstract your repositories: With clean separation between domain logic and persistence, you can change databases later with minimal impact.
How Near Coding Designs MVP Data Layers
At Near Coding, we take a future-first approach to data architecture. Even at the MVP stage, we implement patterns that simplify scaling later: structured migrations, clear domain boundaries, and efficient caching strategies.
Whether we use PostgreSQL, MongoDB, or hybrid architectures, our goal is the same: keep data reliable, portable, and adaptable. This ensures our clients can scale seamlessly, without losing months rebuilding their data layer when success hits.
8. Building for Observability: Monitoring, Logging & Metrics from Day One
As MVPs evolve into production systems, what you can’t see will eventually break you. Early-stage teams often focus solely on features and speed—but without proper observability, problems go unnoticed until users complain.
Observability isn’t a luxury. It’s a foundational element of Scalable MVP Development. From the first deployment, your system should be designed to tell you what’s happening inside it—in real time, with traceable insights, and minimal guesswork.
At Near Coding, we implement monitoring and logging strategies in every MVP, no matter how early the stage. It’s not about building enterprise-level dashboards; it’s about giving the product owner and developers visibility into how the product behaves in the wild.
The Three Pillars of Observability
Observability is built on three core pillars: each serving a specific purpose in maintaining and scaling your MVP:
Logging – Records discrete events (errors, transactions, exceptions).
Example: tracking failed login attempts or API timeouts.Metrics – Captures system-wide performance over time.
Example: CPU usage, memory load, response times, and queue lengths.Tracing – Follows individual requests across multiple services or layers.
Example: identifying latency in a multi-step checkout flow or API chain.
Together, these pillars allow developers and operators to understand not only what happened, but why it happened—turning firefighting into controlled iteration.
Diagram: MVP Observability Framework
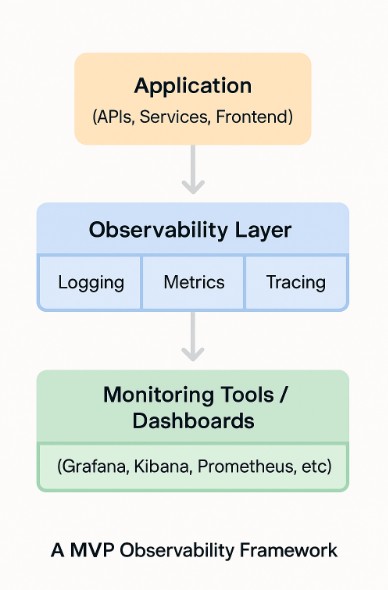
A well-observed MVP tells a story: where it slows, where it breaks, and where it wins.
Best Practices for MVP Observability
Centralize your logs
Use structured logging with correlation IDs. Centralized log aggregators like ELK Stack (Elasticsearch, Logstash, Kibana) or AWS CloudWatch simplify debugging and make trends visible across services.Define key metrics early
Track what matters: request rates, latency, error ratios, and user activity. For MVPs, 10 well-chosen metrics beat 100 random ones.Use tracing to connect the dots
Tools like OpenTelemetry or Jaeger help you trace a single user request through multiple components, vital when scaling to multiple APIs or microservices.Set up alerting thresholds
Use Prometheus, Datadog, or Azure Monitor to send real-time alerts when thresholds are breached (e.g., memory usage > 80%, failed payments spike, or API latency doubles).Monitor both system and business metrics
Beyond CPU and memory, track metrics that reflect customer experience: login success rate, API uptime, and checkout completions.
Observability in Action: The Developer and Business Impact
For Developers: Debugging becomes faster, reproducible, and data-driven. When issues arise, you see the exact API call, payload, and error chain, no more blind hunts.
For Product Owners: Observability reveals usage patterns, customer behavior, and early performance bottlenecks, turning data into insight for roadmap decisions.
For the Company: It builds reliability and trust. Users experience fewer outages, teams deploy faster, and business stakeholders get confidence in system health.
That’s the silent advantage of Custom MVP Development done right: observability turns uncertainty into control.
Recommended MVP Observability Stack

These tools provide lightweight yet powerful observability setups, perfectly suited for MVPs that want to scale with confidence.
This approach doesn’t just reduce risk, it increases velocity. At Near Coding clients ship faster, fix smarter, and scale without chaos because they know what’s happening under the hood.
9. Integrating Third-Party Services Wisely
Third-party services are the secret weapon of MVP speed. They let startups validate ideas faster, reduce development overhead, and deliver polished user experiences without reinventing the wheel. But while they’re powerful accelerators, they can also become long-term liabilities if used carelessly.
The goal of Scalable MVP Development isn’t just to build fast—it’s to build fast without giving away control. Every external dependency should accelerate your launch today and preserve flexibility for tomorrow. That balance is what distinguishes rushed MVPs from well-engineered ones.
The “Borrow, Don’t Bind” Principle
When integrating external APIs or SaaS tools, follow the Borrow, Don’t Bind rule. Use them to extend functionality, not to define it.
Third-party services are perfect for non-core features (things that don’t differentiate your product but are necessary for operations).
Examples include:
Authentication: Auth0, Okta, Firebase Auth.
Payments: Stripe, PayPal, Braintree.
Email & Notifications: SendGrid, Postmark, Twilio.
Analytics: Mixpanel, Segment, Google Analytics.
These services help you focus on what truly matters: your product’s core value proposition. But always integrate through abstraction layers (your own service interfaces), so you can switch providers or bring features in-house later without major rewrites.
Diagram: Third-Party Integration Architecture
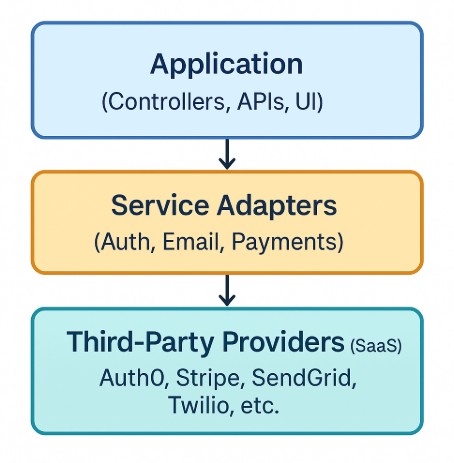
Smart MVPs wrap third-party tools in internal adapters. You keep their power but retain ownership of your architecture.
Why Abstraction Matters
When you directly couple your app to a vendor SDK, you lose flexibility. If that vendor changes APIs, pricing, or availability, your entire system is affected. By introducing a service layer or adapter, you isolate those dependencies behind stable interfaces.
Example:
Later, if you migrate to Postmark or AWS SES, only the adapter changes.
Your controllers, services, and business logic stay untouched.
This small architectural decision saves weeks of refactoring as your MVP matures.
Choosing Wisely: What to Outsource vs. Build
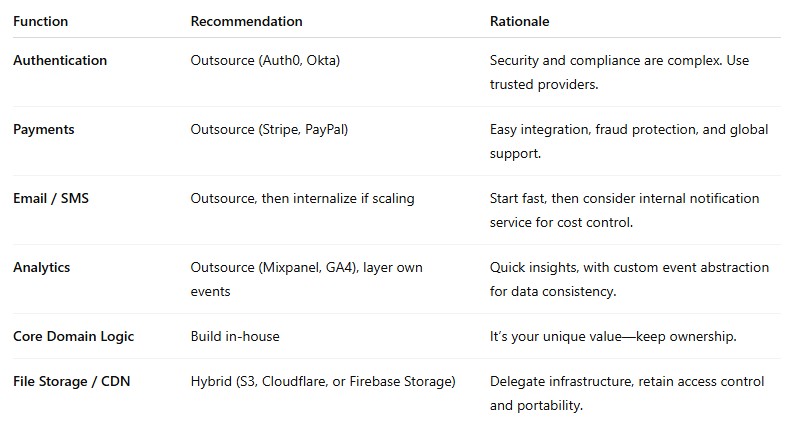
Common Integration Pitfalls
Vendor Lock-In: Relying too heavily on a single SaaS platform. Always keep a migration path.
Data Ownership Risks: Read every provider’s data export and retention policies carefully.
Hidden Costs: API pricing often scales with volume. Plan budgets for growth.
Compliance Overlaps: Ensure third-party services meet GDPR, HIPAA, or SOC2 if applicable.
Error Handling Neglect: Implement retries, backoff, and graceful degradation for failed API calls.
Remember: third-party services can fail too. Your users should never feel that outage.
At Near Coding, we apply a service-adapter-first pattern in every Custom MVP Development project. We integrate only where it adds measurable speed and reliability, never where it compromises flexibility.
Our architecture approach ensures:
Vendor independence with clear interface boundaries.
Consistent API wrappers with centralized error handling.
Configurable environment-based integration (test, staging, production).
Seamless replacement of vendors as the product scales.
This way, our clients enjoy all the advantages of rapid SaaS integration—without getting trapped by it.
10. Common MVP Anti-Patterns and How to Avoid Them
Every developer and founder wants to build an MVP that scales, but many fall into the same traps.
These are patterns that feel productive at first but quietly sabotage growth, reliability, and maintainability down the road.
Recognizing and avoiding these early can save months of frustration and thousands in technical debt.
At Near Coding, we’ve reviewed and refactored dozens of early-stage products. The same mistakes appear repeatedly: shortcuts taken in the name of speed that ultimately slow everything down. Let’s unpack the most common ones and how to avoid them.
1. Spaghetti Code Monoliths
The Problem:
Many MVPs start as a single, massive codebase with no boundaries. Business logic, API routes, and database calls are mixed together, making it nearly impossible to test or refactor.
Why It Happens:
Teams prioritize shipping over structure, believing they’ll “clean it up later.” But later rarely comes.
The Fix:
Adopt a modular monolith approach (as detailed in Section 5). Use domain-based folders, service classes, and repository patterns from day one. You’ll move just as fast, but you’ll scale much farther.
2. Hard-Coupled Dependencies
The Problem:
Directly tying your app to frameworks, SDKs, or third-party APIs makes it brittle. When a provider changes an endpoint or pricing model, your product breaks, or your budget does.
The Fix:
Always code against interfaces, not implementations. Introduce adapters for external services (see Section 9). This adds a single layer of indirection that buys infinite flexibility.
3. Database Over-Engineering (or Under-Design)
The Problem:
Some teams over-normalize every table; others dump everything into one collection. Both extremes create bottlenecks. Over-design limits iteration, while under-design creates chaos once relationships matter.
The Fix:
Keep it simple but intentional. Define clear entity boundaries, enforce foreign keys where needed, and always version your schema with migrations. For Scalable MVP Development, data should evolve, not explode.
4. “Prototype Forever” Mentality
The Problem:
An MVP becomes the production system, and nobody ever goes back to solidify it. Test coverage stays at 10%, no documentation exists, and “quick hacks” become permanent architecture.
The Fix:
Schedule refactoring sprints as part of your roadmap. Every few iterations, clean, document, and re-evaluate. The cost of ignoring this is exponential.
5. Missing DevOps Discipline
The Problem:
Manual deployments, untracked environments, and “works-on-my-machine” bugs plague early MVPs. Without automation, even small releases feel risky.
The Fix:
Implement a lightweight CI/CD pipeline from the beginning (see Section 6). It doesn’t have to be enterprise-grade, just automated and repeatable.
6. Ignoring Observability
The Problem:
When something breaks, you don’t know where or why. Without logs, metrics, or alerts, your team spends days guessing.
The Fix:
Integrate observability tools (Grafana, Kibana, Prometheus) from day one. Even minimal logging provides critical visibility into your system’s health.
7. Premature Optimization
The Problem:
Developers over-engineer for scale before there’s traffic. Complex caching, asynchronous pipelines, and container orchestration drain time and focus.
The Fix:
Focus on clarity before cleverness. Build for maintainability first, then performance. Optimize only once you have real data to justify it.
8. Lack of Clear Ownership
The Problem:
When every developer touches every file, accountability disappears. Bugs resurface, conventions drift, and onboarding new engineers becomes painful.
The Fix:
Assign clear ownership per module or domain. Use code review policies and consistent naming conventions. Ownership drives pride and quality.
How to Stay Out of the Anti-Pattern Trap

These are not just technical improvements—they’re business accelerators. Each one shortens the time between idea and iteration, reducing friction for your team and risk for your stakeholders.
Near Coding’s Perspective
At Near Coding, we treat MVPs like launch platforms, not throwaway prototypes. Our process includes automated testing, architecture audits, and DevOps pipelines, even in the earliest sprints. This ensures that by the time your product reaches traction, you’re scaling on solid ground, not on a pile of patches.
We believe in MVP Architecture Best Practices because we’ve seen their ROI firsthand: faster iteration, happier developers, and fewer 2 a.m. emergencies.
11. Practical Architecture Blueprint: A Scalable MVP in Action
By now, we’ve explored the principles, patterns, and decisions that separate fragile MVPs from those that scale with confidence. But let’s put theory into practice.
What does a Scalable MVP Architecture actually look like when it all comes together? Below is a simplified blueprint that combines the structural, technological, and operational layers we’ve discussed, from frontend and backend to database and DevOps, into one cohesive ecosystem.
Architecture Overview
A well-designed MVP is a system where each layer has one clear responsibility, but all layers work in harmony. The architecture should allow quick feature delivery today while keeping refactoring and scaling painless tomorrow.
Diagram: End-to-End Scalable MVP Blueprint
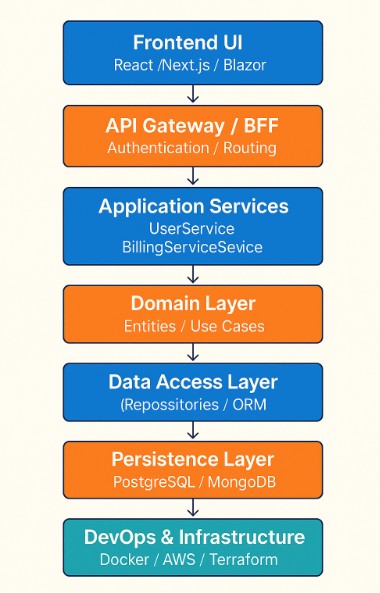
A scalable MVP architecture balances modularity with simplicity where each layer is replaceable, testable, and independently evolvable.
How the Pieces Work Together
Frontend (React / Next.js / Blazor)
Provides user interaction and renders dynamic content. Communicates with APIs through a well-defined gateway.API Gateway / Backend-for-Frontend (BFF)
Routes requests, handles authentication, and translates between frontend needs and backend microservices or monolith endpoints.Application Services
Contain the core business workflows (e.g., user registration, billing, notifications). Built around MVP Architecture Best Practices, each service encapsulates its logic with clean dependencies.Domain Layer
Represents your product’s “heart.” Contains entities, rules, and invariants that define your unique business logic, making it the layer least likely to change as your MVP evolves.Data Access Layer
Abstracts database operations with repository and unit-of-work patterns. It isolates persistence logic, making database swaps or ORM migrations easy.Persistence Layer
Houses your relational and non-relational stores. Relational (PostgreSQL, MySQL) handles structured, transactional data; NoSQL (MongoDB, Redis) supports caching, events, and flexible documents.DevOps & Infrastructure
Handles deployments, scaling, monitoring, and resilience. Tools like Docker, AWS ECS, and Terraform ensure repeatability and cloud portability.
Technical Benefits
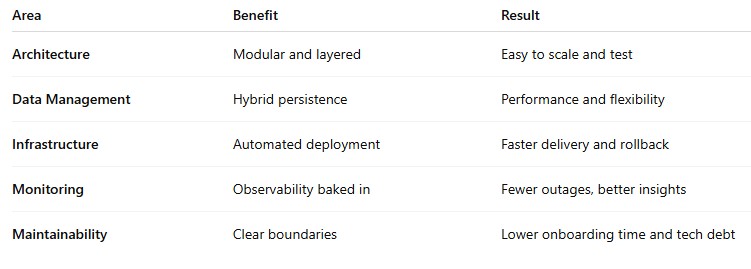
This architecture is production-ready. It’s how modern teams ship MVPs that adapt quickly to change.
How This Helps Teams and Product Owners
Developers get a clean, maintainable codebase that supports continuous delivery.
Product Owners can release features confidently, knowing that architecture won’t slow them down.
CTOs gain flexibility—whether scaling horizontally, migrating to microservices, or onboarding new engineers.
End Users experience better performance and fewer outages.
In short, the architecture supports both innovation and stability—the two pillars of successful MVP evolution.
At Near Coding, this architecture is more than a template—it’s a proven framework.
We adapt it to each client’s needs, combining the right technologies with MVP Architecture Best Practices to ensure:
Faster launch cycles
Seamless scalability
Predictable infrastructure costs
Reduced maintenance overhead
Whether we’re building an MVP for a SaaS platform, fintech startup, or enterprise innovation lab, this foundation enables Custom MVP Development that stands the test of growth and time.